k8s总结知识点
1、k8s基本概念和术语
k8s相关组件介绍:
api service:所有服务访问统一入口。对外暴露K8S的api接口,是外界进行资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
crontroller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等,它们是处理集群中常规任务的后台线程。
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;就是监视新创建的 Pod,如果没有分配节点,就选择一个节点供他们运行,这就是pod的调度。
etcd:一个可信赖的分布式键值存储服务,能够为整个分布式集群存储一些关键数据,协助分布式集群运转。储存K8S集群所有重要信息(持久化)。v2版本时基于内存的存储,v3开始才是序列化到介质。新版本K8S(v1.11以上)已经改用v3版本etcd。
kubelet:直接跟容器引擎交互实现容器的生命周期管理。
kube-proxy:负责写入规则至 IPTABLES、IPVS 实现服务映射访问的。
其中scheduler和controller-manager两个组件是有leader选举的,这个选举机制是k8s对于这两个组件的高可用保障。api server是可以水平扩展的。
其他重要插件:
coredns:可以为集群中的SVC创建一个域名IP的对应关系解析
dashboard:给 K8S 集群提供一个 B/S 结构访问体系
ingress controller:官方只能实现四层代理,INGRESS 可以实现七层代理
federation:提供一个可以跨集群中心多K8S统一管理功能
prometheus :提供K8S集群的监控能力
elk:提供 K8S 集群日志统一分析介入平台
标签——污点(Taint),避免新的容器被调度到该Node上。而如果某些Pod可以(短期)容忍(Toleration)某种污点的存在
2、二进制安装
https://www.hqq365.com/index.php/archives/306/
3、POD
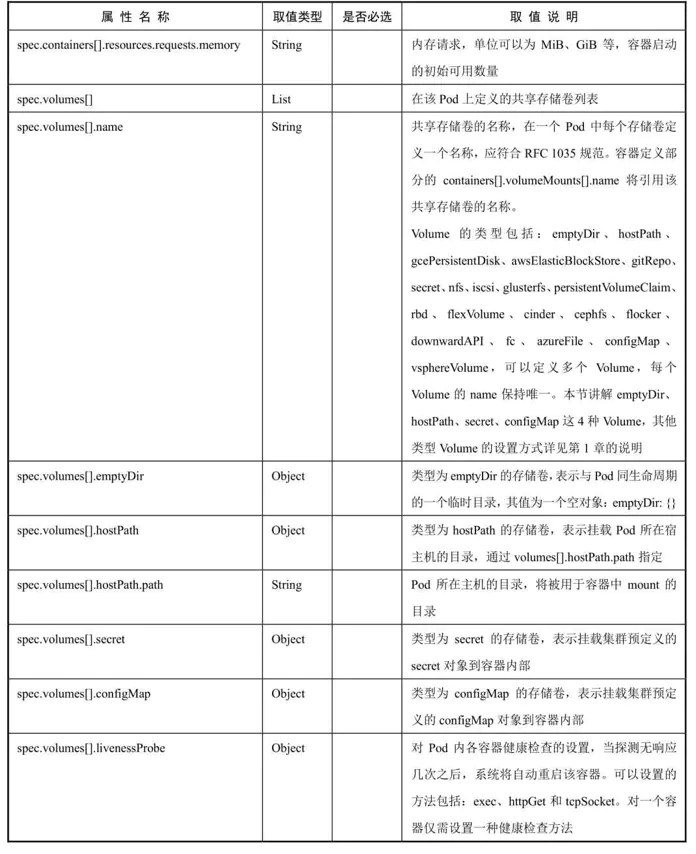
Pod容器共享Volume
同一个Pod中的多个容器能够共享Pod级别的存储卷Volume。
Volume可以被定义为各种类型,多个容器各自进行挂载操作,将一个
Volume挂载为容器内部需要的目录
ConfigMap概述
ConfigMap供容器使用的典型用法如下。
(1)生成容器内的环境变量。
(2)设置容器启动命令的启动参数(需设置为环境变量)。
(3)以Volume的形式挂载为容器内部的文件或目录。
(4)编写代码在 Pod 中运行,使用 Kubernetes API 来读取 ConfigMap
1、通过kubectl命令行方式创建
可以使用 kubectl create configmap 从文件、目录或者 key-value 字符串创建等创建 ConfigMap
(1)通过--from-file参数从文件中进行创建
$ echo hello > test1.txt
$ ehco world > test2.txt
$ kubectl create configmap my-config --from-file=key1=test1.txt --from-file=key2=test2.txt
$ kubectl describe configmap my-config(2)通过文件夹创建configmap
$ mkdir config
$ echo hello > config/test1
$ echo world > config/test2kubectl create configmap dir-config --from-file=config/
看到该configmap资源中有两个键值对,test1:hello和test2:world,key为文件名,value为文件内容
(3)通过键值对创建configmap$ kubectl create configmap literal-config --from-literal=key1=hello --from-literal=key2=world
2、通过yaml文件创建
#config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: my-config
data:
key1: hello
key2: worldkubectl create -f config.yaml
1.配置到容器的环境变量
# test-pod-configmap.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pod-configmap
spec:
containers:
- name: test-busybox
image: busybox
imagePullPolicy: IfNotPresent
args:
- sleep
- "86400"
env:
- name: KEY1 #定义环境变量的名称
valueFrom: # key "KEY1"对应的值
configMapKeyRef:
name: my-config #环境变量的值取自my-config
key: key1 #key 为key1
- name: KEY2
valueFrom:
configMapKeyRef:
name: my-config
key: key2$ kubectl create -f test-pod-configmap.yaml
- 设置为命令行参数
# test-pod-configmap-cmd
apiVersion: v1
kind: Pod
metadata:
name: test-pod-configmap-cmd
spec:
containers:
- name: test-busybox
image: busybox
imagePullPolicy: IfNotPresent
command: [ "/bin/sh","-c","echo $(KEY1) $(KEY2)"]
env:
- name: KEY1
valueFrom:
configMapKeyRef:
name: my-config
key: key1
- name: KEY2
valueFrom:
configMapKeyRef:
name: my-config
key: key2
restartPolicy: Never创建pod,该pod成功启动后会输出环境变量KEY1和KEY2的值
$ kubectl create -f test-pod-configmap-cmd.yaml
3.将configmap挂载到容器中
# test-pod-projected-configmap-volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pod-projected-configmap-volume
spec:
containers:
- name: test-pod-busybox
image: busybox
imagePullPolicy: IfNotPresent
args:
- sleep
- "86400"
volumeMounts:
- name: config-volume #引用volume的名称
mountPath: "/projected-volume" #挂载的容器的目录
readOnly: true
volumes:
- name: config-volume #定义volume的名称
projected:
sources:
- configMap:
name: my-config #使用configmap my-config$ kubectl exec -it test-pod-projected-configmap-volume -- /bin/sh
查看挂在到容器中的文件内容
/ # cd projected-volume/
/projected-volume # ls
key1 key2通过volume挂载和环境变量的区别
通过Volume挂载到容器内部时,当该configmap的值发生变化时,容器内部具备自动更新的能力,但是通过环境变量设置到容器内部该值不具备自动更新的能力。
注意:
ConfigMap必须在Pod使用它之前创建
使用envFrom时,将会自动忽略无效的键
Pod只能使用同一个命名空间的ConfigMap
ConfigMap无法用于静态Pod。
Deployment或RC
使用yaml创建Deployment
k8s deployment资源创建流程:
- 用户通过 kubectl 创建 Deployment。
- Deployment 创建 ReplicaSet。
- ReplicaSet 创建 Pod。
对象的命名方式是:子对象的名字 = 父对象名字 + 随机字符串或数字
apiVersion: apps/v1 #版本号
kind: Deployment #类型
metadata: #元数据
name: #rs名称
namespace: #所属命名空间
labels: #标签
controller: deploy
spec: #详情描述
replicas: #副本数量
revisionHistoryLimit: #保留历史版本,默认是10
paused: #暂停部署,默认是false
progressDeadlineSeconds: #部署超时时间(s),默认是600
strategy: #策略
type: RollingUpdates #滚动更新策略
rollingUpdate: #滚动更新
maxSurge: #最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavaliable: #最大不可用状态的pod的最大值,可以为百分比,也可以为整数
selector: #选择器,通过它指定该控制器管理哪些pod
matchLabels: #Labels匹配规则
app: nginx-pod
matchExpressions: #Expression匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80扩缩容
kubectl scale deploy deploy名称 --replicas=pod数量 -n 命名空间
kubectl edit deploy deploy名字 -n 命名空间
回滚deployment
发布失败时需要回滚。
第一步:执行命令 kubectl rollout history deployment.v1.apps/nginx-deployment 检查 Deployment 的历史版本。
第二步:执行命令 kubectl rollout history deployment.v1.apps/nginx-deployment --revision=2,查看 revision(版本)的详细信息。
第三步:执行命令 kubectl rollout undo deployment.v1.apps/nginx-deployment --to-revision=2 将当前版本回滚到前一个版本。也可以使用 --to-revision 选项回滚到前面的某一个指定版本。
第四步:执行命令 kubectl get deployment nginx-deployment,检查该回滚是否成功,Deployment 是否按预期的运行
金丝雀发布
deployment支持更新过程中的控制,如"暂停(pause)"或"继续(resume)"更新操作
比如有一批新的pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部分还是旧的版本。然后,再筛选一小部分的用户请求路由到新的pod应用,继续观察能否稳定地按期望的方式运行。确定没问题之后再继续完成余下的pod资源滚动更新,否则立即回滚更新操作。这就是所谓的金丝雀发布。
更新deployment版本,并配置暂停deployment
[root@master ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.2 -n dev && kubectl rollout pause deploy pc-deployment -n dev
查看rs,发现老版本rs没有减少,新版本rs增加一个
[root@master ~]# kubectl get rs -n dev
在窗口2中查看deploy状态,发现deploy正在等待更新且已经有1个更新好了
[root@master ~]# kubectl rollout status deploy pc-deployment -n dev
在窗口1中继续deploy的更新
[root@master ~]# kubectl rollout resume deploy pc-deployment -n dev
RC的滚动升级
使用kubectl rolling-update命令进行RC的滚动升级,升级时系统要求新的RC与旧的RC必须在相同的namespace里
# 执行命令滚动升级nginx-rc
kubectl rolling-update nginx-rc -f nginx-rc-rollout-v1.17.yaml
或者
# 直接使用命令更新
kubectl rolling-update nginx-rc --image=nginx:1.17
注:使用命令升级后新RC仍使用旧RC的name
# 如果在更新过程中发现配置有误,则可中断更新,执行以下命令回滚
kubectl rolling-update nginx-rc --image=nginx:1.17 --rollback RC的滚动升级不具有Deployment在应用版本升级过程中的历史记录、新旧版本数量的精细控制等功能
DaemonSet的更新策略
DaemonSet包含两种升级策略:
1)OnDelete:默认的升级策略,使用此策略,在创建好新的DaemonSet配置之后,新的Pod并不会被自动创建,直到用户手动删除旧Pod才会出发新建操作
2)RollingUpdate:使用此策略更新时,旧版的Pod将被自动杀掉,然后自动创建新版的Pod,整改过程与普通Deployment的滚动升级一样可控,但回滚时不能通过kubectl rollback命令完成,必须通过再次提交旧版本配置的方式实现
要启用DaemonSet的滚动更新特性,必须将其spec.updateStrategy.type设置为RollingUpdate。
还可以设置spec.updateStrategy.rollingUpdate.maxUnavailable(默认值为1)和spec.minReadySeconds(默认值为0)
StatefulSet的更新策略
更新策略向Deployment和DaemonSet的策略看齐,也可使用RollingUpdate、Paritioned和OnDelete策略。
NodeSelector:定向调度
通常我们无法知道Pod最终会被调度到哪个节点上。在实际情况下,也可能需要将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,来达到上述目的。
#语法kubectl label nodes <node-name> <label-key>=<label-value>
#示例,如果节点名称是harmonycloud,需要添加‘disktype=ssd’标签kubectl lable nodes harmonycloud disktype=ssd
# 验证,使用如下命令查看是否成功给node添加标签kubectl get nodes --show-labels然后,在Pod的定义中加上nodeSelector的设置
需要注意的是,如果我们指定了Pod的nodeSelector条件,且在集群中不存在包含相应标签的Node,则即使在集群中还有其他可供使用的Node,这个Pod也无法被成功调度。
NodeAffinity:Node亲和性调度
NodeAffinity 意为Node 亲和性的调度策略, 是用于替换NodeSelector的全新调度策略。目前有两种节点亲和性表达。
◎ requiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上(功能与nodeSelector很像,但是使用的是不同的语法),相当于硬限制。
◎ preferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先后顺序。
硬策略
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodeType
operator: In
values:
- dev3.2.软策略
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: nodeType
operator: In
values:
- testNodeAffinity语法支持的操作
符包括In、NotIn、Exists、DoesNotExist、Gt、Lt。虽然没有节点排斥功能,但是用NotIn和DoesNotExist就可以实现排斥的功能了。
NodeAffinity规则设置的注意事项如下。
◎ 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条
件都得到满足,Pod才能最终运行在指定的Node上。
◎ 如果nodeAffinity指定了多个nodeSelectorTerms,那么其中一
个能匹配成功即可。
◎ 如果在nodeSelectorTerms中有多个matchExpressions,则一个
节点必须满足所有matchExpressions才能运行该Pod。
PodAffinity:Pod亲和与互斥调度策略
Pod的亲和性和互斥性调度具体作法,就是通过在Pod上定义上增加topologyKey属性,来声明对应的目标拓扑区域内几种相关联的Pod“在一起或不在一起”。与节点亲和性相同,Pod亲和性与互斥的条件设置也是requireDuringSchedulingIgnoredExecution和preferredDuringSchedulingIgnoredExecution。Pod的亲和性被定义与PodSpec的affinity字段的podAffinity子字段中;Pod间的互斥性被定义与同一层次的PodAntiAffinity。
Pod亲和性调度测试
1.参数目标pod
首先创建一个名为pod-flag的Pod,带有标签security=S1和app=nginx,后面例子将使用到pod-flag作为Pod亲和性和互斥的目标Pod:
apiVersion: v1
kind: Pod
metadata:
name: pod-flag
labels:
security: "S1"
app: "nginx"
spec:
containers:
- name: nginx
image: nginxPod 亲和性调度
创建2个Pod来说明Pod亲和性调度,定义亲和性标签"security=S1"对应上面Pod "pod-flag",topologyKey的值被设置为 "kubernetes.io/hostname" :
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: nginx创建Pod之后,使用kubectl get pod -o wide 查看,两个Pod被调度到同一个k8s-node-01上。
pod-affinity 1/1 Running 0 10m 10.255.44.8 k8s-node-01 <none> <none>
pod-flag 1/1 Running 0 13m 10.255.44.7 k8s-node-01 <none> <none>Pod互斥性调度测试
创建3个Pod,希望它不与目标Pod运行在同一个Node上。
apiVersion: v1
kind: Pod
metadata:
name: anti-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubetnetes.io/hostname
containers:
- name: anti-affinity
image: nginxTaints和Tolerations(污点和容忍)
第10关 k8s架构师课程之一次性和定时任务
Service
Service用于为一组提供服务的Pod抽象一个稳定的网络访问地址,Service能够提供负载均衡的能力,但是在使用上有以下限制:只提供 4 层负载均衡能力。
Service主要用于提供网络服务,通过Service的定义,能够为客户端应用提供稳定的访问地址(域名或IP地址)和负载均衡功能,以及屏蔽后端Endpoint的变化,是Kubernetes实现微服务的核心资源.
service yaml 详细解析
kind: Service #类型为service
apiVersion: v1 #service API版本, service.apiVersion
metadata: #定义service元数据,service.metadata
name: sgame-node-s10000 # 定义Service名称
namespace: jszx #定义命名空间
labels: #自定义标签,service.metadata.labels
app: sgame-node-s10000 #定义service标签的内容
annotations: # 备注
creator: admin # 创建人
spec: #定义service的详细信息,service.spec
ports:
- name: http-10001 # 定义端口名称
protocol: TCP # 定义协议
port: 10001 # service端口
targetPort: 10001 # 目标pod端口
nodePort: 31000 # 对外暴露的端口
- name: http-3600
protocol: TCP
port: 3600
targetPort: 3600
nodePort: 32000
selector: #service的标签选择器,定义要访问的目标pod
app: sgame-s10000 #将流量路到选择的pod上,须等于Deployment.spec.selector.matchLabels
version: v1 # 同上两者条件满足时生效
type: NodePort #service的类型,定义服务的访问方式,默认为ClusterIP, service.spec.type
sessionAffinity: None
externalTrafficPolicy: ClusterService在 K8s中有以下四种类型:
① ClusterIp
默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP
② NodePort
在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过: NodePort来访问该服务。
③ LoadBalancer
在NodePort的基础上,借助Cloud Provider创建一个外部负载均衡器,并将请求转发到NodePort
④ ExternalName
把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 Kubernetes 1.7或更高版本的kube-dns才支持。
{kind=link}
{kind=link}